

Журнал высшей нервной деятельности им. И.П. Павлова, 2021, T. 71, № 4, стр. 563-577
Влияние периодичности и гласности звука на ответы слуховой коры мозга детей
Т. А. Строганова 1, К. С. Комаров 1, Д. Е. Гояева 1, Т. С. Обухова 1, Т. М. Овсянникова 1, А. О. Прокофьев 1, Е. В. Орехова 1, 2, *
1 Центр нейрокогнитивных исследований (МЭГ-Центр), Московский государственный психолого-педагогический университет
Москва, Россия
2 MedTech West and the Institute of Neuroscience and Physiology, Sahlgrenska Academy, the University of Gothenburg
Gothenburg, Sweden
* E-mail: orekhova.elena.v@gmail.com
Поступила в редакцию 23.11.2020
После доработки 19.12.2020
Принята к публикации 22.12.2020
Аннотация
Механизмы мозга человека, направленные на декодирование звуков речи, представляют как фундаментальный, так и практический интерес для многих областей нейронауки. Настоящая работа посвящена роли периодичности и речевой природы (фиксированной формантной структуры) гласных звуков в модуляции активности слуховой коры мозга у типично развивающихся детей. Мы предположили, что, хотя обе этих характеристики свойственны гласным звукам речи, их обработка осуществляется разными нейронными сетями слуховой коры. Для проверки этой гипотезы мы сконструировали набор акустических стимулов, манипулируя их периодичностью и гласностью по отдельности, и использовали магнитоэнцефалографию в сочетании с индивидуальными моделями поверхности коры мозга для оценки кортикальной топографии источников и силы ответов слуховой коры мозга. Выборку составили девять типично развивающихся детей в возрасте 7–12 лет. Мы обнаружили высокую чувствительность ранних ответов слуховой коры (50–150 мс после начала стимула) как к периодичности, так и к гласности звука, при независимой настройке нейронных сетей на каждое из этих свойств звуков речи. Различия в локализации, временной динамике и полушарной асимметрии этих дифференциальных ответов указывали на то, что “зоны гласности звука” в височной коре являются наиболее ранним уровнем в иерархии обработки речевой информации, на котором обработка собственно акустических свойств периодического звука трансформируется в декодирование звуков речи. Полученные результаты позволят оценить специфику и роль возможных нарушений обработки низкоуровневых свойств речевых звуков в трудностях восприятия речи у детей с первазивными расстройствами развития.
Устная речь представляет особую ценность для видовой коммуникации, и настройка слуховой системы на обработку звуков родной речи – одна из основных черт обработки слуховой информации в мозге человека (Fitch, 2000). Предполагают, что существование выделенных зон височной коры мозга, кодирующих звуки “своей” речи (Belin и др., 2004), связано именно с биологической важностью речевых звуков. Исследования показывают, что настройка на определенные звуки, а также их обработка специализированными нейронными сетями не являются врожденными. Младенцы постепенно приобретают ее в течение первого года жизни, начиная точнее различать гласные и согласные звуки, которые представлены в их речевой среде, чем звуки “чужих” языков ((Maurer, Werker, 2014); для обзора см. Narayan, 2019). У взрослых людей настройка на звуки родной речи вызывает серьезные проблемы в различении ряда звуков речи иностранной (Strange, Shafer, 2008). Сравнительно недавно были открыты высокоспециализированные зоны височной коры, осуществляющие акустический анализ звуков голоса (Belin и др., 2004; Pernet и др., 2015) и высоты основного тона периодических, сложных по спектральному составу звуков, таких как речь и музыка (Patterson et al., 2002). Эти работы, использующие метод функциональной магнитно-резонансной томографии (фМРТ), создали основу новых направлений в изучении нейронных основ базовых процессов обработки речевых сигналов в норме и при патологии мозга. Трудности восприятия речи на слух, характерные для первазивных нарушений развития и, в частности, для детей с расстройствами аутистического спектра (Schelinski, von Kriegstein, 2020), могут быть связаны с аномалиями в формировании зон “обработки звуков речи” в раннем онтогенезе, а также с дальнейшим снижением функциональной эффективности и скорости обработки речи. Однако прогресс в этом направлении сдерживается малочисленностью нейрофизиологических исследований специфики декодирования звуков речи в мозге нейротипичных детей.
Настоящая работа посвящена роли периодичности и гласности звуков в модуляции суммарной нейронной активности различных зон слуховой коры мозга у типично развивающихся детей в возрасте 7–12 лет. Мы предположили, что, хотя обе эти характеристики свойственны гласным звукам речи, их обработка у детей, как и у взрослых, осуществляется разными нейронными сетями слуховой коры. Для проверки гипотезы мы сконструировали набор акустических стимулов, манипулируя их периодичностью и гласностью по отдельности, и использовали магнитоэнцефалографию (МЭГ) в сочетании с индивидуальными моделями поверхности коры мозга для оценки топографии и силы нейронных ответов слуховой коры мозга. Этот метод нейровизуализации, в отличие от фМРТ, позволяет не только локализовать источник нейронной активности, характеризующей дифференциальную обработку периодических звуков и/или гласных звуков речи, но и оценить скорость, с которой мозг декодирует соответствующую черту акустического стимула. Временные параметры обработки акустической информации особенно важны для речевого потока, в котором длительность одного гласного звука варьирует между 70 и 250 мс, в зависимости от многих собственно лингвистических факторов, а также от индивидуальных особенностей говорящего (Hillenbrand et al., 2000). За это время звук должен распознаваться мозгом слушателя, несмотря на вариации в абсолютных характеристиках формант, характеризующих речь разных людей, накладывающийся шум и другие помехи. Поэтому мы ожидали, что латентный период дифференциального нейронного ответа на “гласность” и/или периодичность акустического стимула не будет превышать 100 мс при нормальной работе мозга у нейротипичных детей. Исходя из результатов предыдущих МЭГ-исследований (Gutschalk et al., 2004; Gutschalk, Uppenkamp, 2011), мы сфокусировали внимание на особом компоненте вызванного слухового ответа – медленном негативном сдвиге силы тока источников слуховой коры, порождающем так называемое “устойчивое поле” (sustained field, SF). В отличие от обычных транзиторных слуховых компонентов МЭГ-ЭЭГ (P50, P100, N100), которые возникают в ответ на любой слуховой стимул и модулируются множеством факторов, SF не вызывается короткими стимулами, чувствителен к периодичности и гласности сложного звука (Gutschalk, Uppenkamp, 2011) и, предположительно, отражает работу несинхронизированных нейронных популяций за пределами первичной слуховой коры (Steinmann, Gutschalk, 2011).
МЕТОДИКА
В исследовании участвовали 9 мальчиков в возрасте 7–12 лет (Ср. = 9.6; CO = 1.2). Согласно медицинской документации, у детей не было в анамнезе неврологических или нервно-психических нарушений (в том числе нарушений слуха). Уровень их интеллекта (батарея тестов Кауфманов второго пересмотра; Kaufman, 2004) находился в пределах нормативных значений. Все дети дали устное согласие на проведение исследования после того, как его цели и процедура были им подробно объяснены. Родители всех детей подписали информированное согласие. Протокол исследования был одобрен этическим комитетом Московского государственного психолого-педагогического университета.
Слуховые стимулы
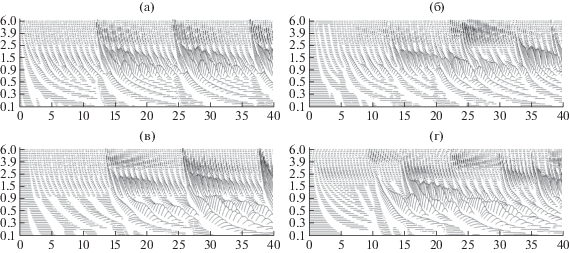
Мы предъявляли 4 типа стимулов, сконструированных из набора затухающих синусоид с экспоненциальным понижением амплитуды, чтобы имитировать пульсации речевого тракта. Помимо трех периодических гласных со звучанием как в ударных слогах или в начале слова, были сгенерированы три класса контрольных стимулов, для которых мы нарушали либо периодичность гласной, либо неизменность ее формантного состава, либо то и другое вместе (рис. 1). Все стимулы были отфильтрованы фильтром низких частот с полосой пропускания 100 кГц и 12 дБ/окт, что соответствует наклону спектральной огибающей человеческой речи. Интенсивность всех стимулов была уравнена по нормированным оценкам их общей мощности. Стимулы предъявляли бинаурально с громкостью 60 дБ относительно стандартного порога слышимости. Сглаживание проводили с помощью 10 мс окна (косинус). Длительность каждого стимула составляла 800 мс. Подробное описание стимулов дано в работе (Uppenkamp et al., 2006). В кратком изложении: в состав стимульного материала входили четыре типа слуховых раздражителей, подаваемых в псевдослучайном порядке. (1) Три периодические гласные с фиксированной частотой формант (фонетическая транскрипция: [а], [и], [о]). Для них затухающие синусоиды повторялись с периодом 12 мс (83 Гц). Несущие частоты синтезированных гласных были фиксированы на уровне частот 4 нижних формант и соответствовали их типичному диапазону в голосе взрослого мужчины. (2) Непериодические гласные с теми же фиксированными частотами формант, в которых периодичность появления затухающих синусоид была нарушена смещениями в окне ±6 мс. Эти стимулы воспринимались как гласные звуки речи с неопределенной частотой основного тона. (3) Периодические негласные звуки, в которых несущие частоты 4 нижних формант гласных звуков варьировались по отдельности случайным образом в пределах октавы. В отличие от гласных звуков, эти стимулы воспринимались как “музыкальный дождь”. (4) Непериодические негласные звуки, в которых нарушалась и периодичность, и константность формант. Такие стимулы воспринимались как “булькающий” звук.
Рис. 1.
Слуховые стимулы. (а) – периодический речевой (гласный) звук; (б) – непериодический речевой (гласный) звук; (в) – неречевой звук с периодической огибающей; (г) – непериодический неречевой звук. На каждой из четырех панелей показаны спектрограммы первых 40 мс звучания соответствующих стимулов: горизонтальная ось – время от начала звучания (мс), вертикальная ось – частоты спектральных пиков (кГц). Фундаментальная частота периодических звуков – 83 Гц (период 12 мс). Объяснения в тексте.
Fig. 1. Four types of stimuli used in the experiment. (а) – periodic speech (vowel) sound; (б) – non-periodic speech (vowel) sound; (в) – non-speech sound with periodic envelope; (г) – non-periodic non-speech sound. Each of the four panels shows a spectrogram of the respective sounds during the first 40 ms after the stimulus onset. Horizontal axis – time in milliseconds, vertical axis – frequency in kHz. Fundamental frequency of periodic sounds in the two left panels is 83 Hz (12 ms period). See text for more detailed explanation.
Регистрация МЭГ
Перед началом эксперимента с помощью устройства трехмерной оцифровки “FASTRAK” (Polhemus, США) определяли координаты анатомических реперных точек, а также индикаторных катушек индуктивности. Магнитоэнцефалограмму регистрировали с помощью 306-канального аппаратно-программного комплекса “VectorView” (Elekta Neuromag Oy, Финляндия). Запись магнитоэнцефалограммы (МЭГ), электромиограммы (ЭМГ) и электрокардиограммы (ЭКГ) производили с частотой дискретизации 1000 Гц при полосе пропускания 0.1–330 Гц. Положение головы относительно массива сенсоров в ходе эксперимента отслеживалось в реальном времени с помощью индикаторных катушек индуктивности. Длительность экспериментальной сессии составляла около 25 мин. После завершения сессии проводили МЭГ-МРТ корегистрацию (наложение системы координат МЭГ на индивидуальные МРТ-изображения мозга).
Обработка данных МРТ
С помощью пакета “FreeSurfer” (Dale et al., 1999) из индивидуальных снимков структурной МРТ реконструировали поверхность коры головного мозга с индивидуальным расположением борозд и извилин. В результате топографически корректная поверхность коры была представлена в виде оболочки (mesh), описываемой координатами узлов и системой трехточечных симплексов, формируемых этими узлами. Типичная оболочка содержала около 7500 симплексов в каждом полушарии. При визуализации для облегчения восприятия полученная поверхность была “развернута” (“раздута”) для более удобного просмотра (Fischl et al., 1999). Затем полученные индивидуальные реконструкции поверхности мозга были приведены к стандартному мозгу (Colin 27) с помощью пакета “FreeSurfer”. Полученная модель “обобщенной” по всем испытуемым поверхности коры мозга была использована при анализе данных МЭГ.
Обработка данных МЭГ
Удаление артефактов записи и коррекцию положения головы проводили с помощью метода пространственно-временнoго разделения сигналов (программа “MaxFilter”; Elekta Neuromag Oy, Финляндия). Для удаления кардиографических и электроокулографических артефактов использовали анализ независимых компонент (independent component analysis, ICA), встроенный в пакет программ “BrainStorm” (Tadel et al., 2011). Эпоха анализа составляла от –200 до 800 мс относительно начала подачи стимула, число “чистых” эпох в среднем составило (Ср. = 73.7; СО = 10.1) на каждый тип звука (напр., периодический гласный “а”). Для каждого испытуемого вызванные магнитные поля градиентометров усредняли относительно момента начала подачи слухового стимула и нормировали на предстимульный интервал (от –200 до 0 мс). Усреднение проводили отдельно для каждого из четырех типов стимулов.
На следующем шаге реконструировали локализацию и силу тока источников, лежащих в коре мозга и генерирующих соответствующий магнитный ответ. Так как компонент SF представляет собой медленно развивающийся ответ мозга, вызванные поля были отфильтрованы с верхним срезом фильтра, равным 20 Гц. Реконструкцию осуществляли с помощью реализованного в программном пакете “MNE” метода распределенного моделирования “sLORETA” (standardized low-resolution brain electromagnetic tomography, Pascual-Marqui, 2002). На поверхность коры каждого полушария накладывалась сеть из приблизительно 7500 диполей (источников), имеющая форму рекурсивно разделенного октаэдра. Возможные направления всех диполей были фиксированы по нормали к поверхности коры ±20 град. Анализировали значения плотности силы тока в источниках. Дальнейший анализ слуховых вызванных магнитных полей проводили, ограничивая зону поиска источников в соответствии с предыдущими данными об источниках их генерации. В нее входили зоны коры в левом и правом полушариях мозга, включающие слуховую кору и граничащие с нею области коры (“Destrieux cortical atlas”, (Destrieux et al., 2010)): височная плоскость верхневисочной извилины, поперечная височная извилина Гершля, поперечная височная борозда, полюсная плоскость верхневисочной извилины, внутренний сегмент круговой извилины островка, латеральная поверхность верхневисочной извилины и восходящая часть латеральной борозды.
На первом этапе анализа мы определяли пространственные координаты максимума SF в левом и правом полушариях. С этой целью для каждого испытуемого мы вычислили координаты MNI (система координат Монреальского Неврологического Института) максимально активированного источника в среднем по всем четырем типам стимулов и по интервалу 200–800 мс после начала их подачи. На основании этих данных были оценены среднегрупповые значения координат максимума активации и статистические различия в координатах максимума нейронного ответа в зависимости от типа стимуляции. Затем, чтобы найти зону интереса (ЗИ) для статистического анализа временной динамики SF в зависимости от типа стимула, мы по абсолютным значениям тока определили 30 максимально активированных источников в том же интервале анализа. Индивидуальные данные, учитывающие направление тока источников в соответствующих ЗИ, рассматривали как зависимую переменную при статистическом анализе зависимости амплитуд сигнала МЭГ (как мгновенных, так и интегрированных по коротким временным интервалам) от основных экспериментальных факторов – периодичности и гласности звука.
Статистический анализ
Для статистического анализа использовали пакет “Statistica” (TIBCO Software Inc, США). Для исследования различий в не нормально распределенных значениях пространственных координат максимумов SF для четырех типов стимулов использовали непараметрический дисперсионный анализ (ANOVA) Фридмана. Для поточечного сравнения временных различий в амплитуде силы тока источников SF в ортогональных парных контрастах (гласный/негласный звук или периодический/непериодический звук) применяли критерий Вилкоксона–Манна–Уитни. Для поправки на множественные сравнения использовали метод контроля ложных эффектов (false discovery rate, FDR). Принятый уровень значимости – p < 0.05 (с поправкой FDR). Для исследования различий в раннем временном диапазоне SF в зависимости от полушария и времени, прошедшего с момента начала подачи стимула, проводили дисперсионный анализ с факторами повторных измерений: Периодичность, Гласность, Полушарие и Время. Зависимой переменной была амплитуда силы тока источников слуховой коры, интегрированная по 50 мс интервалам времени от 0 до 250 мс относительно момента подачи стимула. При необходимости делали поправку Гринхауза–Гейссера для коррекции нарушения сферичности. Значимость парных сравнений проверяли post hoc, используя метод Тьюки (Tukey honest difference test).
РЕЗУЛЬТАТЫ ИССЛЕДОВАНИЙ
Расположение максимума SF в слуховой коре и его зависимость от типа стимула
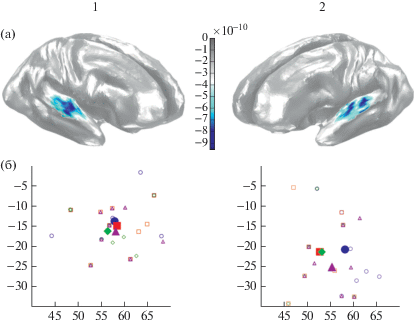
На рис. 2 представлен пространственный паттерн активации в коре левого и правого полушарий в среднем по всем 4 типам стимулов и по интервалу 200–800 мс после начала их подачи. Усредненный по всем типам стимулов максимум SF в левом (x = –55.1; y = = –22.0; z = 6.0) и правом полушариях (x = = 57.8; y = –15.1; z = 4.4) располагался на медиолатеральной поверхности верхневисочной борозды в области поперечной борозды/извилины Гершля. Непараметрический дисперсионный анализ показал, что в левом полушарии тип стимула влияет на смещение максимума в медиолатеральном направлении (Friedman ANOVA Chi Sqr. (N = 9, df = 3) = = 11.52; p = 0.009). Непериодические негласные звуки активировали наиболее медиально расположенную часть верхневисочной борозды, тогда как и периодичность (M-U: непериодические против периодических негласных z = 1.85; p = 0.06), и гласность звука (M-U гласные против негласных непериодических: z = 2.37; p = 0.018) смещали нейронный ответ к латеральной ее поверхности. В рострокаудальном направлении общий эффект типа стимула не достигал уровня значимости (ANOVA Chi Sqr. (N = 9, df = 3) = 4.29; p = 0.23). Однако периодические гласные, максимально близкие к естественным звукам речи, явно сопровождались более каудальным расположением максимума ответа слуховой коры, по сравнению как с “испорченными” непериодическими гласными (z = = 2.02; p = 0.04), так и с негласными периодическими стимулами (z = 1.75; p = 0.08). В правом полушарии тип стимула значимо не изменял координаты максимума SF по какой-либо пространственной оси.
Рис. 2.
Локализация источников SF в слуховой коре мозга. (а) – усредненная по группе испытуемых плотность тока источников SF в общем максимуме ответа (все 4 типа стимулов объединены) в правом (1) и левом (2) полушариях. Области затемнения соответствуют негативной ориентации источников тока, интенсивность затемнения – амплитуда тока источников в шкале sLORETA. Общий для всех стимулов максимум активации расположен на медиолатеральной поверхности верхневисочной борозды. (б) – относительные смещения MNI-координат источников максимума SF в зависимости от типа стимула. По горизонтальной и вертикальной осям – MNI-координаты в миллиметрах по оси x (medial–lateral) и оси y (posterior–anterior). Маленькие незаполненные фигуры – локализация индивидуальных максимумов, большие заполненные – локализация среднегрупповых максимумов. Круг – неречевые непериодические звуки, квадрат – речевые (гласные) непериодические, ромб – неречевые периодические, треугольник – речевые периодические.
Fig. 2. Cortical localization of the sustained field (SF) in the right (1) and left (2) auditory cortex. (а) – grand average of the SF source current density in the response maximum (responses to all stimuli are pooled together). Shaded areas marks negative direction of the current, shade intensity corresponds to the source current amplitude in the sLORETA unites. The SF maximum is both hemispheres localized to medial-lateral surface of the superior temporal gyrus. (б) – stimulus-related shift in the position of the SF maxima. MNI coordinates of the sources (in mm) are given in the horizontal plane: x axis – medial–lateral, y axis – posterior–anterior. Small open figures correspond to individual coordinates; big filled shapes show the group means. Circle – nonvowels/nonperiodic, square – vowels/nonperiodic, rhomb – nonvowels/periodic, triangle – vowels/periodic. Please, note the lateral shift of the maximal activation for both periodic and speech-like stimuli.
Динамика вызванного нейронного ответа слуховой коры в зонах интереса в левом и правом полушариях и ее зависимость от периодичности и гласности звуков представлены на рис. 3. Общий паттерн слухового ответа в обоих полушариях был схож для всех предъявленных стимулов. Первым после начала подачи стимула появлялся обязательный “детский” позитивный компонент Р100m (Orekhova et al., 2013), за которым на протяжении всего времени подачи стимула следовал длительный ответ корковых источников тока негативной направленности (SF). Несмотря на различия в направлении тока источников обязательных компонентов вызванных слуховых ответов у детей и у взрослых (Edgar et al., 2015; Orekhova et al, 2013), компонент SF у детей в нашей выборке был схож с таковым у взрослых людей при длительном предъявлении слуховых стимулов (см., например, Gutschalk, Uppenkamp, 2011).
Рис. 3.
Независимое влияние речевой природы и периодичности звуков на временную динамику SF. (а) – контраст между периодическими (сплошная линия) и непериодическими (прерывистая линия) неречевыми звуками в левом (слева) и правом (справа) полушариях мозга. (б) – контраст между гласными (сплошная линия) и неречевыми непериодическими (прерывистая линия) звуками в левом (слева) и правом (справа) полушариях мозга. 1 – общий паттерн ответов слуховой коры (групповое усреднение). По горизонтальной оси время в миллисекундах, 0 мс соответствует началу подачи звука, 800 мс – завершению стимуляции. По вертикальной оси – условные значения (единицы sLORETA) силы тока корковых источников в максимуме активации. 2 – разностные волновые формы ответов слуховой коры для соответствующих контрастов. Области вокруг каждой кривой соответствуют диапазону ошибки среднего значения силы тока источника.
Fig. 3. Independent modulation of the SF source current timecourse by sounds’ periodicity and vowelness. (а) – sound’s periodicity: contrast between periodic (solid line) and nonperiodic (dashed line) nonvowels in left and right hemisphere. (б) – sound’s vowelness: contrast between nonvowels (solid line) and nonperiodic vowels (dashed line) in left and right hemisphere. 1 – the grand average waveforms of the auditory evoked response at the source level. Horizontal axis – time in milliseconds, 0 and 800 ms correspond to onset and offset of the stimulus respectively. 2 – the grand average subtraction waveforms for the sound’s periodicity and vowelness. Shaded areas around the curves designate standard error of means.
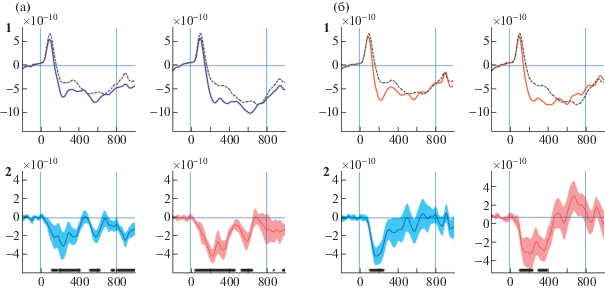
Для того чтобы оценить влияние периодичности и гласности звуков на SF независимо друг от друга, мы рассматривали два ортогональных (полностью независимых) контраста: 1) периодические и непериодические негласные звуки (тем самым полностью мы исключили влияние гласности на сигнал мозга и оставили лишь эффект периодичности) и 2) гласные и негласные непериодические звуки (в этом случае мы оставили исключительно эффект “гласности” звука). Как видно из рис. 3 (а), периодичность звука усиливала негативный компонент SF в слуховой коре как левого, так и правого полушарий на протяжении всего временного интервала подачи. Известно, что в первые 100–200 мс после подачи звука обязательные транзиторные компоненты слухового нейронного ответа у взрослых (N100m, P200m) и у детей (Р100m, P200m) накладываются на постепенно развивающийся компонент SF, препятствуя анализу его ранней динамики (Gutschalk et al., 2004). Тем не менее контраст между периодическими и непериодическими звуками, демонстрируя непрерывность увеличения “негативной” силы тока корковых источников для периодических звуков, позволяет выявить особенности компонента SF в раннем интервале его возникновения (см. рис. 3). Действительно, периодические стимулы усиливают ответ негативных источников, сначала уменьшая позитивность Р100m, а затем увеличивая негативность SF (см. рис. 3 (а)). В результате эффект периодичности влияет на компонент SF начиная с 50 мс после начала подачи звука в правом полушарии и со 100 мс в левом. Гласность непериодических звуков (см. рис. 3 (б)) также усиливает негативный компонент SF в обоих полушариях, начиная приблизительно со 100 мс после момента подачи гласного звука. В сравнении с периодичностью эффект гласности в компоненте SF был более коротким и длился примерно 300–500 мс в зависимости от полушария.
Учитывая высокую скорость кодирования звуков речи в слуховой коре, особый интерес вызывает сравнительно ранний интервал SF, совпадающий с фронтом его нарастания в период времени от 50 до 250 мс после начала звука. Поэтому мы провели дисперсионный анализ нейронных ответов слуховой коры в этом временном диапазоне, при этом зависимой переменной была амплитуда силы тока источников SF слуховой коры, интегрированная по интервалам времени в 50 мс. Дисперсионный анализ выявил сильные ($\eta _{p}^{2}$ > 0.8) и высокозначимые (p < 0.0001) эффекты периодичности и гласности звука, а также их значимую зависимость от полушария и времени, прошедшего с момента начала подачи стимула (табл. 1).
Таблица 1.
Результаты дисперсионного анализа SF в первые 250 мс после начала подачи стимула. Эффекты гласности, периодичности и их взаимодействия с полушарием и временем нейронного ответа. Table 1. ANOVA results for the SF in the first 250 ms after stimulus onset: effects of ‘Vowelness’, Periodicity and their interaction with Hemisphere and Time.
| F | Adj.p | G-G epsilon | $\eta _{p}^{2}$ | |
|---|---|---|---|---|
| Периодичность | 61.56 | <0.0001 | 0.88 | |
| Гласность | 114.9 | <0.0001 | 0.93 | |
| Периодичность*Гласность | 7.95 | 0.022 | 0.70 | |
| Периодичность*Полушарие | 5.98 | 0.040 | 0.57 | |
| Периодичность*Время | 40.33 | <0.0001 | 0.50 | 1.00 |
| Гласность*Время | 42.29 | <0.0001 | 0.52 | 1.00 |
| Периодичность*Гласность*Полушарие | 10.99 | 0.01 | 0.83 | |
| Периодичность*Гласность*Время | 20.46 | <0.0001 | 0.53 | 1.00 |
| Периодичность*Гласность*Полушарие*Время | 10.92 | 0.00026 | 0.65 | 0.99 |
Примечание: Приведены значимые эффекты факторов повторных измерений Гласность (Глас), Периодичность (Период), Полушарие (Полуш) и Время, а также их взаимодействия. F – величина F-значения, adj.p – вероятность ошибки 1 рода, скорректированная на нарушение сферичности дисперсий по уровням факторов, G-G epsilon – поправка Гринхауза–Гейссера, $\eta _{p}^{2}$ – мера величины соответствующего эффекта. Note: F-values and adj.p (probability of error of the 1st type corrected for violation of sphericity – homogeneity of variance at the factor's levels), G-G epsilon is the Greenhouse–Geisser estimate of sphericity, $\eta _{p}^{2}$ is a measure of the value of the corresponding effect size.
Как периодичность, так и гласность звука резко усиливали SF в обоих полушариях на всем временном интервале анализа, причем эффект периодичности, но не гласности, был сильнее в правой слуховой коре, чем в левой (Периодичность*Полушарие F(1.8) = 5.98; adj.p = 0.04). Значимая зависимость эффекта периодичности от времени объяснялась тем, что он возникал между 50 и 100 мс, затем усиливался к 150 мс и оставался постоянным до 250 мс (для всех парных сравнений скорректированная на число сравнений Tukey HSD значимость p < 0.001). В отличие от периодичности, гласность звука начинала значимо влиять на SF слуховой коры только между 100 и 150 мс (Tukey HSD: p < 0.001), хотя затем ее эффект был больше, чем эффект периодичности, вплоть до конца интервала анализа. Более поздний и более сильный эффект гласности (по сравнению с эффектом периодичности) подтверждается значимостью тройного взаимодействия Период*Глас*Время (F(4.32) = 20.46; adj. р < 0.0001; см. также рис. 4). Интересно, что несколько значимых взаимодействий (табл. 1: Периодичность*Гласность; Период*Глас*Полуш; Период*Глас*Полуш*Время) указывают на то, что соединение в звуке гласности и периодичности имеет сильное аддитивное влияние на компонент SF слуховой коры. Post hoc анализ сложного четырехфакторного взаимодействия Период*Глас*Полуш*Время (F(4.32) = = 10.42; adj. р = 0.00026) показал, что на нисходящем переднем фронте компонента SF периодичность гласного звука ускоряла дифференциальный ответ на него в правом полушарии (см. рис. 5) и резко усиливала негативность коркового SF в том же полушарии (Период*Глас*Полуш для временного интервала 100–150 мс : F(1, 8) = = 34.972, p = 0.00036).
Рис. 4.
Различия во временной динамике дифференциальных ответов источников SF в слуховой коре на периодичность и гласность звуков – результаты ANOVA. Слева – контраст “периодические – непериодические”, справа – контраст “речевые (гласные) – неречевые” звуки. Сплошная линия – непериодические (слева) или неречевые (справа) стимулы; прерывистая линия – периодические (слева) или речевые (справа) стимулы. По горизонтальной оси – 50 мс интервалы времени от начала подачи стимула: 50 мс соответствует первому 50 мс интервалу после начала подачи стимула, 250 мс – интервалу от 200 до 250 мс. По вертикальной оси – условные значения (единицы sLORETA) среднего по интервалу значения силы тока корковых источников в максимуме активации. Вертикальными линиями обозначена стандартная ошибка среднего значения. Скорректированные (Tukey HSD) p-значения в парных сравнениях: * – p < 0.05; *** – p < 0.0005; **** – p <0.0001.
Fig. 4. Stimulus-related difference in temporal dynamics of the SF – ANOVA effects of periodicity and vowelness of the complex sound. Left panel – periodicity of the sound. Right panel – vowelness of the sound. Solid and dashed lines mark non-periodic and periodic stimuli in the left panel and non-speech stimuli and vowels in the right panel. Horizontal axis represents the successive 50 ms time intervals after the stimulus onset: 50 ms corresponds to the first post-onset interval, 250 ms – to the post onset time interval from 200 ms up to 250 ms. Vertical axis – source current density averaged across the 50 ms intervals in arbitrary sLORETA units. Vertical lines designate a standard error of mean. Asterisks denote significant differences (Tukey HSD) for the respective comparisons: * – p < 0.05; *** – p < < 0.0005; **** – p < 0.0001.
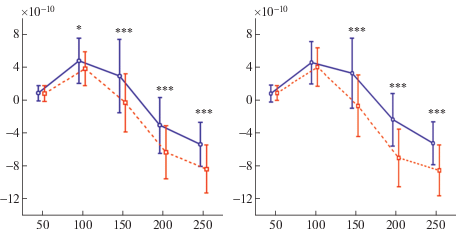
Рис. 5.
Полушарная асимметрия различий во временной динамике дифференциальных ответов источников SF слуховой коры на гласность звука в зависимости от его периодичности – результаты ANOVA. Левая сторона – контраст “речевые – неречевые” для непериодических стимулов в левом (1) и правом (2) полушариях; правая сторона – тот же контраст для периодических стимулов. Сплошные линии – неречевые звуки, прерывистые линии – речевые. Остальные обозначения как на рис. 4. Post-hoc сравнения (Tukey HSD test) показали, что в правом полушарии различия между гласными и неречевыми звуками возникают раньше и проявляются сильнее, если оба типа звуков – периодические.
Fig. 5. Hemispheric differences in the cumulative effect of periodicity and vowelness on the SF temporal dynamics – ANOVA results. Left-side panels – contrast vowels/nonvowels for nonperiodic stimuli. Right-side panels – the same contrast for periodic stimuli. In each panel: 1 – left hemisphere, 2 – right hemisphere. Solid and dashed lines designate non-vowels and vowels respectively. All other designation as in Fig. 4. Post-hoc comparisons (Tukey HSD test) show that the SF response in the right hemisphere appears faster and has a greater strength for the periodic vowels than for any other type of presented sounds.
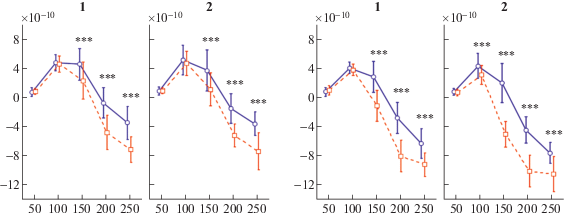
Таким образом, результаты ANOVA подтвердили и расширили выводы, сделанные по результатам ортогональных контрастов эффектов периодичности и гласности звука на компонент SF слуховой коры, указав на особую роль сочетания спектральной структуры и периодичности в гласных звуках естественной речи.
ОБСУЖДЕНИЕ РЕЗУЛЬТАТОВ
В данной работе, используя МЭГ и метод распределенного моделирования активности корковых источников, мы исследовали дифференциальную чувствительность слуховой коры мозга детей к гласным звукам речи и к периодическим неречевым звукам. На основании предыдущих фМРТ-исследований мы предполагали, что слуховая кора должна обладать независимой чувствительностью к обоим свойствам гласных звуков речи – периодичности (регулярной повторяемости сложного спектра сигнала во времени) и гласности (четкой формантной структуре спектра). Для проверки этой гипотезы мы искажали в контрольных стимулах либо периодичность неречевого звука (эффект периодичности), либо формантный состав непериодического, но все еще речевого звука (эффект гласности), либо то и другое вместе в неречевых непериодических звуках и отслеживали влияние этих манипуляций на нейронный ответ слуховой коры левого и правого полушарий мозга. Второй методологической особенностью нашего исследования был анализ особой формы суммарного нейронного ответа слуховой коры, так называемого устойчивого магнитного поля (SF), отражающего постепенное нарастание общего деполяризационного сдвига дендритных потенциалов больших групп нейронов под влиянием длительного звукового сигнала (Steinmann, Gutschalk, 2011).
В подтверждение исходной гипотезы мы обнаружили избирательную чувствительность корковых источников SF к гласности и периодичности звука. В соответствии с данными фМРТ (Patterson et al., 2002; Pernet et al., 2015) локализация корковых источников обоих дифференциальных ответов была сдвинута к латеральной поверхности верхневисочной извилины, по сравнению с более медиальным их расположением для “испорченных” непериодических негласных звуков. Принципиально новым результатом работы был факт чрезвычайно раннего (через 50–100 мс после начала подачи звука) возникновения дифференциальных нейронных ответов SF на переднем фронте волны устойчивой негативности (рис. 3), причем ответ на периодичность звука опережал ответ на гласность. Еще одно различие между ответами проявилось в межполушарной асимметрии: ответ на периодичность был латерализован к правому полушарию (где он возникал раньше и был сильнее, чем в левом), тогда как ответ на гласность и по латентности, и по величине был одинаков в обоих полушариях. Более того, оказалось, что комбинация периодичности и гласности в звуках естественной речи способствует особенно быстрому развитию дифференциального ответа на “естественные гласные” в слуховой коре правого полушария. Нужно подчеркнуть, что при малом объеме выборки здоровых детей (9 испытуемых) мы выявили сильные статистически значимые эффекты влияния периодичности и гласности на силу и динамику компонента SF (табл. 1). Можно предположить, что в основе ранней избирательной чувствительности компонента SF к этим чертам звуковых сигналов лежат автоматические процессы их кодирования в специализированных зонах слуховой коры мозга, характерные для всех типично развивающихся детей.
При интерпретации модуляций компонента SF мы опирались на гипотезу о нейронных механизмах SF, связывающую источники его генерации с активностью несинхронизированных нейронных популяций в зонах слуховой коры, декодирующих периодичность или гласность звука и расположенных у человека на медиальной и латеральной поверхности верхневисочной извилины (Bendor, Wang, 2006; Steinmann, Gutschalk, 2011). Наиболее убедительные свидетельства в ее пользу относятся к кодированию периодичности. Декодирование высоты основного тона периодических слуховых сигналов происходит за счет нарастающей частоты разрядов нейронных популяций в так называемом “центре обработки периодичности” (pitch processing center). Он находится в антеролатеральной части извилины Гершля, наружно по отношению к более медиально расположенной первичной слуховой коре А1 (Bendor, Wang, 2006). Нейронные исследования рострального поля ядра слуховой коры обезьян – гомолога антеролатеральной области у человека – показали, что чем выше частота основного тона в спектре периодического сигнала, тем выше частота разрядов нейронов в центре обработки высоты сложного звука (Bendor, Wang, 2008). Более того, часть нейронов этой зоны имеют сложные рецептивные поля, отвечающие на гармонические колебания частоты основного тона в спектре сложного сигнала, но не в чистом тоне. В суммарной нейронной активности, регистрируемой методами МЭГ и ЭЭГ, устойчивый сдвиг возбудимости нейронных популяций проявляется в величине суммарного “негативного” тока источников SF, который, как и частота нейронных разрядов в центре обработки периодичности, усиливается при увеличении частоты основного тона (Steinmann, Gutschalk, 2011). Считают, что на этом уровне обработки происходит реконструкция временной динамики спектра звука, интегрирующая информацию о возбуждении отдельных частотных каналов, приходящую из первичной слуховой коры (Bendor, Wang, 2006). Компонент SF, вызванный звуками голоса, также может отражать несинхронизированную активность нейронных популяций в “височных областях обработки голоса” (temporal voice areas, TVA; Pernet et al., 2015), избирательно чувствительных к соответствию общей структуры формант гласным звукам речи. Эти зоны расположены вдоль медиолатеральной поверхности верхневисочной извилины, в том числе в задней ее части. Согласно данным фМРТ, “зоны голоса” сильнее активируются звуками голоса, чем средовыми звуками или другими акустическими контрольными стимулами, но мало чувствительны к надсегментарным аспектам фонетики речи, таким как слоговая структура, ритм и т.д. Результаты фМРТ указывают на билатеральное расположение “зон голоса” без какого-либо преимущества одного из полушарий в силе дифференциального ответа на гласные звуки речи (Pernet et al., 2015).
Таким образом, полученные нами данные, в целом, согласуются с данными литературы о кортикальной топографии и полушарной асимметрии “зон голоса” и “зон высоты основного тона” в мозге взрослого человека. Латеральное смещение корковых источников SF, вызванной и периодическими, и гласными звуками, вторит данным МЭГ и фМРТ (Pernet et al., 2015; Ritter et al., 2005) о расположении центров обработки периодичности и одного из центров гласности на стыке извилины Гершля с областью латерального височного пояса. Полагают, что обе корковых области обеспечивают вход в вентральный поток обработки слуховой информации в коре, вовлеченный в дальнейшую интеграцию акустической информации на надсегментарном уровне и ее мультимодальную репрезентацию (в том числе семантические ассоциации) (Ries et al., 2019). Тенденция к более каудальной локализации корковых источников SF на периодические гласные звуки в сравнении со звуковыми стимулами остальных типов (рис. 2) подтверждается данными Паттерсона и соавторов, полученными при анализе SF у взрослых людей (Patterson et al., 2016). Кроме того, эта тенденция соответствует сведениям о расположении основного “центра гласности” в средне-задней части верхневисочной извилины (для обзора см. DeWitt, Rauschecker, 2012). и “центра периодичности” в средне-передней области той же извилины (Griffiths, 2003). Различие в полушарной асимметрии ответа SF на периодичность и гласность звуков также хорошо укладывается в известные представления. Выраженная правосторонняя асимметрия в чувствительности компонента SF к периодичности речевых и неречевых звуков (рис. 3, 5) воспроизводит данные МЭГ (Ross и др., 2005) у взрослых людей. Интерпретируют такие данные обычно как результат преимущества правого полушария в обработке низкочастотной составляющей спектра гармонического звука, которое служит основой для латерализации восприятия музыки и эмоциональной интонации речи. С другой стороны, отсутствие такого правополушарного доминирования в силе и скорости ответа SF на звук голоса у детей (рис. 3) подтверждает аналогичные данные SF, полученные у взрослых людей (Fan и др., 2017), а также результаты многочисленных других нейрофизиологических (см. мета-обзор Manca, Grimaldi, 2016) и фМРТ-работ (Pernet et al., 2015), указывающие на билатеральную активацию центров гласности в ответ на соответствующие стимулы. Возможное объяснение этого факта – равноценное, хотя и взаимодополнительное участие обоих полушарий в детекции формантной структуры акустического сигнала и определение его соответствия одному из эталонов нейронных репрезентаций гласных звуков в “центрах голоса”.
В отличие от компонента SF, обнаруживаемого в данных МЭГ, BOLD-сигнал фМРТ (в силу известной особенности метода) не проясняет, с какой скоростью сравнительно низкоуровневые специализированные зоны слуховой коры обрабатывают информацию о периодичности и гласности звуков речи. Наиболее интересной и новой находкой нашей работы стали данные о различиях в скорости работы специализированных областей слуховой коры, выделяющих эти перцептивно значимые признаки акустического сигнала.
Значимый дифференциальный ответ SF на периодичность неречевого звука возникал в правом полушарии уже через 50 мс после начала его подачи и достигал пика в интервале 100–150 мс (рис. 3, 5). К сожалению, оценки связи латентности и временной динамики раннего ответа SF у взрослых людей с периодичностью и гласностью звука в литературе отсутствуют (см., например, Gutschalk et al., 2004). Однако наши результаты созвучны немногочисленным данным МЭГ взрослых людей, полученным в парадигме POR (pitch onset response), в рамках которой исследуется ответ мозга на возникновение периодичности в непрерывном шумовом сигнале при появлении фрагментов регулярно модулируемого шума (regular interval noise). Риттер и соавт. (Ritter et al., 2005) исследовали возможности мозга дискриминировать частоту основного тона при ее изменении в регулярно модулируемом шуме. Они показали, что, при условии отчетливого восприятия испытуемыми основного тона в акустическом сигнале, пиковая латентность дифференциального ответа “негативных” корковых источников сигнала МЭГ составляет в среднем около 100 мс и варьирует от 50 до 140 мс в зависимости от частоты модуляций шума (см. рис. 7 в Ritter et al., 2005). Более того, латентность POR при смене высоты тона была обратно пропорциональна высоте тона в “новом” стимуле и высоко коррелировала с субъективным восприятием испытуемыми относительной высоты тона. Таким образом, оценки латентности реакции мозга на периодичность неречевого сигнала, полученные в двух исследованиях с использованием МЭГ, удивительно совпадают, несмотря на различия в возрасте испытуемых, дизайне эксперимента, методах моделирования корковых источников и т.д. Судя по исследованию Риттера и соавторов, мозг не только распознает периодичность спектрально сложного сигнала через 50–100 мс после возникновения, но и декодирует высоту его основного тона.
В сравнении с периодичностью дифференциальный ответ SF слуховой коры обоих полушарий на речевую природу звука имел более длительную латентность, начинаясь со 100 мс после момента начала подачи стимула, но уже через 40–50 мс достигал максимума и угасал (рис. 3). Временная задержка в возникновении дифференциального ответа SF на гласность звука по сравнению с периодичностью (средняя латентность около 50 мс для периодических неречевых стимулов и 110 мс для непериодических гласных) позволяет предположить, что распознавание мозгом идентичности гласных звуков требует более длинного окна временнóй интеграции, чем кодирование частоты основного тона акустических сигналов. Косвенным свидетельством тому являются также психофизические данные о влиянии укорочения/удлинения звучания гласных на надежность их распознавания в речевом потоке (Ferguson, Kewley-Port, 2007; Hillenbrand et al., 2000). Длительность гласных звуков в речи варьирует от 70 до 250 мс, в зависимости от собственно фонетических свойств определенной гласной, ударности, коартикуляционных изменений и многих других факторов (см. мета-анализ Hillenbrand et al., 2000). Несмотря на значительные вариации, укорочение средней длительности гласных до 100 мс снижает их распознаваемость в слогах типа “согласная – гласная – согласная” (Stevens, 1959), причем необычное укорочение гласных в таких слогах влияет на восприятие больше, чем их необычное удлинение (Hillenbrand et al., 2000). Интересно, что удлинение звучания гласных в среднем в 1.3–2 раза улучшает распознаваемость речи в целом и является существенной особенностью так называемой “ясной” речи, употребляемой, например, в разговоре с иностранцами (Behrman et al., 2019). Таким образом, исследования восприятия показывают, что декодирование гласного звука в слуховой коре занимает в среднем не менее 100 мс, причем некоторое удлинение времени, отведенного мозгу на анализ идентичности гласных, улучшает восприятие речевого потока. Хронометраж распознавания гласных в речевом потоке полностью согласуется с нашими данными о появлении дифференциального нейронного ответа на гласность примерно через 110 мс после начала предъявления звука и достижении им максимума еще спустя 40–50 мс. Различия в скорости ответов SF на гласность и периодичность звука указывают на то, что обработка гласности звука происходит на более высоком уровне слухового вентрального потока, который, предположительно, интегрирует информацию о частоте основного тона гласного звука с его формантным составом. Об этом также свидетельствует аддитивность влияния периодичности и гласности на динамику развития и силу дифференциального ответа SF (рис. 5). Сочетание двух характеристик, максимально приближающее звук к гласному звуку естественной речи, резко усиливало ответ SF, генерирумый “зонами гласности” правого полушария через 100–150 мс после начала предъявления. Такое усиление подтверждает, что на этом, более позднем этапе обработки “зоны гласности” в слуховой коре получают восходящий сигнал о периодичности и высоте основного тона гласного звука. Предполагают, что более низкоуровневая информация о частоте основного тона используется обоими полушариями мозга для нормализации гласной при анализе формантного состава, чтобы отделить перцептивно значимую информацию о соотношении частот формант от изменчивости их абсолютных значений (Andermann et al., 2017; Patterson, Irino, 2014). Латерализация аддитивного эффекта к правому полушарию может быть функционально релевантна его роли в определении половой принадлежности, гендера или даже эмоционального состояния говорящего, которое в значительной степени основывается на частоте основного тона (Belin et al., 2004).
В целом паттерн локализации источников и временные параметры дифференциальных ответов слуховой коры на гласность и периодичность в нашем исследовании согласуются с теоретическими представлениями о том, что “зоны гласности звука” в височной коре являются наиболее ранним уровнем в иерархии обработки речевой информации, на котором обработка собственно акустических свойств стимула трансформируется в декодирование звуков речи.
ЗАКЛЮЧЕНИЕ
Сочетание пространственной локализации и временных свойств суммарного устойчивого поля нейронов слуховой коры указывает на высокую чувствительность относительно ранних ответов слуховой коры в интервале 50–150 мс после начала подачи стимула как к периодичности, так и к речевой природе звука при независимой настройке нейронных сетей обоих полушарий мозга на каждый из этих признаков гласных звуков речи. Латентность дифференциального нейронного ответа на речевую природу звука существенно задержана, по сравнению с ответом на его периодичность, при этом сочетание обоих признаков в гласном звуке естественной речи усиливает и ускоряет нейронный ответ. Полученные результаты соответствуют современным теоретическим моделям формирования нейронных репрезентаций периодических и гласных звуков в слуховой коре мозга человека. Высокая надежность закономерностей, выявленных у типично развивающихся детей, позволяет надеяться, что разрабатываемый подход позволит оценить специфику и роль возможных нарушений обработки низкоуровневых свойств речевых звуков в трудностях восприятия речи у детей с первазивными расстройствами развития.
Список литературы
Andermann M., Patterson R.D., Vogt C., Winterstetter L., Rupp A. Neuromagnetic correlates of voice pitch, vowel type, and speaker size in auditory cortex. NeuroImage. 2017. 158: 79–89.
Behrman A., Ferguson S.H., Akhund A., Moeyaert M. The Effect of Clear Speech on Temporal Metrics of Rhythm in Spanish-Accented Speakers of English. Language and speech. 2019. 62 (1): 5–29.
Belin P., Fecteau S., Bedard C. Thinking the voice: neural correlates of voice perception. Trends in cognitive sciences. 2004. 8 (3): 129–135.
Bendor D., Wang X. Cortical representations of pitch in monkeys and humans. Current opinion in neurobiology. 2006. 16 (4): 391–399.
Bendor D., Wang X. Neural response properties of primary, rostral, and rostrotemporal core fields in the auditory cortex of marmoset monkeys. Journal of neurophysiology. 2008. 100 (2): 888–906.
Dale A.M., Fischl B., Sereno M.I. Cortical surface-based analysis. I. Segmentation and surface reconstruction. NeuroImage. 1999. 9 (2): 179–194.
Destrieux C., Fischl B., Dale A., Halgren E. Automatic parcellation of human cortical gyri and sulci using standard anatomical nomenclature. NeuroImage. 2010. 53 (1): 1–15.
DeWitt I., Rauschecker J.P. Phoneme and word recognition in the auditory ventral stream. Proceedings of the National Academy of Sciences of the United States of America. 2012. 109 (8): E505–514.
Edgar J.C., Fisk Iv C.L., Berman J.I., Chudnovskaya D., Liu S., Pandey J., Herrington J.D., Port R.G., Schultz R.T., Roberts T.P. Auditory encoding abnormalities in children with autism spectrum disorder suggest delayed development of auditory cortex. Molecular autism. 2015. 6: 69.
Fan C.S., Zhu X., Dosch H.G., von Stutterheim C., Rupp A. Language related differences of the sustained response evoked by natural speech sounds. PloS one. 2017. 12 (7): e0180441.
Ferguson S.H., Kewley-Port D. Talker differences in clear and conversational speech: acoustic characteristics of vowels. Journal of speech, language, and hearing research : JSLHR. 2007. 50 (5): 1241–1255.
Fitch W.T. The evolution of speech: a comparative review. Trends in cognitive sciences. 2000. 4 (7): 258–267.
Fischl B., Sereno M.I., Dale A.M. Cortical surface-based analysis: II: inflation, flattening, and a surface-based coordinate system. Neuroimage. 1999. 9(2): 195–207.
Griffiths T.D. Functional imaging of pitch analysis. Annals of the New York Academy of Sciences. 2003. 999: 40–49.
Gutschalk A., Patterson R.D., Scherg M., Uppenkamp S., Rupp A. Temporal dynamics of pitch in human auditory cortex. NeuroImage. 2004. 22 (2): 755–766.
Gutschalk A., Uppenkamp S. Sustained responses for pitch and vowels map to similar sites in human auditory cortex. NeuroImage. 2011. 56(3): 1578–1587.
Hillenbrand J.M., Clark M.J., Houde R.A. Some effects of duration on vowel recognition. The Journal of the Acoustical Society of America. 2000. 108 (6): 3013–3022.
Kaufman A. KABC-II: Kaufman Assessment Battery for Children, 2nd Edn. AGS Pub. Circle Pines, MN; 2004.
Manca A.D., Grimaldi M. Vowels and Consonants in the Brain: Evidence from Magnetoencephalographic Studies on the N1m in Normal-Hearing Listeners. Frontiers in psychology. 2016. 7: 1413.
Maurer D., Werker J.F. Perceptual narrowing during infancy: a comparison of language and faces. Developmental psychobiology. 2014. 56 (2): 154–178.
Narayan C.R. An acoustic perspective on 45 years of infant speech perception, Part 1: Consonants. Language and Linguistics Compass. 2019. 13 (10): e12352.
Orekhova E.V., Butorina A.V., Tsetlin M.M., Novikova S.I., Sokolov P.A., Elam M., Stroganova T.A. Auditory magnetic response to clicks in children and adults: its components, hemispheric lateralization and repetition suppression effect. Brain topography. 2013. 26 (3): 410–427.
Pascual-Marqui R.D. Standardized low-resolution brain electromagnetic tomography (sLORETA): technical details. Methods and findings in experimental and clinical pharmacology. 2002. 24 Suppl D: 5–12.
Patterson R., Andermann M., Uppenkamp S., Rupp A. Neuromagnetic correlates of the vocal characteristics of vowels in auditory cortex. Proceedings of Meetings on Acoustics. 2016. 25: 050002.
Patterson R., Irino T. Size Matters in Hearing: How the Auditory System Normalizes the Sounds of Speech and Music for Source Size. Perspectives on Auditory Research. Ed. Popper A., Fay R. NY: Springer, 2014. 417–440 pp.
Patterson R.D., Uppenkamp S., Johnsrude I.S., Griffiths T.D. The processing of temporal pitch and melody information in auditory cortex. Neuron. 2002. 36 (4): 767–776.
Pernet C.R., McAleer P., Latinus M., Gorgolewski K.J., Charest I., Bestelmeyer P.E., Watson R.H., Fleming D., Crabbe F., Valdes-Sosa M., Belin P. The human voice areas: Spatial organization and inter-individual variability in temporal and extra-temporal cortices. NeuroImage. 2015. 119: 164–174.
Ries S.K., Piai V., Perry D., Griffin S., Jordan K., Henry R., Knight R.T., Berger M.S. Roles of ventral versus dorsal pathways in language production: An awake language mapping study. Brain and language. 2019. 191: 17–27.
Ritter S., Gunter Dosch H., Specht H.J., Rupp A. Neuromagnetic responses reflect the temporal pitch change of regular interval sounds. NeuroImage. 2005. 27 (3): 533–543.
Ross B., Herdman A.T., Pantev C. Right hemispheric laterality of human 40 Hz auditory steady-state responses. Cerebral cortex. 2005. 15 (12): 2029–2039.
Schelinski S., von Kriegstein K. Brief Report: Speech-in-Noise Recognition and the Relation to Vocal Pitch Perception in Adults with Autism Spectrum Disorder and Typical Development. Journal of autism and developmental disorders. 2020. 50 (1): 356–363.
Steinmann I., Gutschalk A. Potential fMRI correlates of 40-Hz phase locking in primary auditory cortex, thalamus and midbrain. NeuroImage. 2011. 54 (1): 495–504.
Stevens K. The role of duration in vowel identification. Quarterly Progress Report. 1959. 52.
Strange W., Shafer V. 6. Speech perception in second language learners: The re-education of selective perception. 2008. pp. 153–191.
Tadel F., Baillet S., Mosher J.C., Pantazis D., Leahy R.M. Brainstorm: a user-friendly application for MEG/EEG analysis. Computational intelligence and neuroscience. 2011. 2011: 879716.
Uppenkamp S., Johnsrude I.S., Norris D., Marslen-Wilson W., Patterson R.D. Locating the initial stages of speech-sound processing in human temporal cortex. NeuroImage. 2006. 31 (3): 1284–1296.
Дополнительные материалы отсутствуют.
Инструменты
Журнал высшей нервной деятельности им. И.П. Павлова