

Вестник Военного инновационного технополиса «ЭРА», 2022, T. 3, № 3, стр. 289-292
ОБРАБОТКА КОМАНД НА ЕСТЕСТВЕННОМ ЯЗЫКЕ С МЕСТОИМЕНИЯМИ С ПОМОЩЬЮ ЯЗЫКОВЫХ МОДЕЛЕЙ RUT5 И RUBERT
М. С. Скороходов 1, 2, А. В. Грязнов 1, И. А. Молошников 1, Р. Б. Рыбка 1, А. Г. Сбоев 1, 2, *
1 Национальный исследовательский центр “Курчатовский институт”
Москва, Россия
2 Национальный исследовательский ядерный университет “МИФИ”
Москва, Россия
* E-mail: sag111@mail.ru
Поступила в редакцию 15.03.2022
После доработки 20.03.2022
Принята к публикации 20.03.2022
Аннотация
Представлены результаты исследования подходов на базе нейросетевых языковых моделей для поиска и замены местоимений в командах на естественном языке человека робототехническому устройству. Замена местоимений в составных командах на объекты, к которым они относятся, задающих последовательности действий, позволяет повысить точность их интерпретации на языке робота. Такая замена облегчает декомпозицию сложных команд на просто реализуемые односоставные команды. Рассмотрены подходы на базе решения задач корефрентности и генерации текста, основу которых составляют нейросетевые модели RuT5 и RuBERT. Продемонстрирована высокая эффективность подхода в обработке команд на естественном языке, содержащих местоимения, на базе управляющего интерфейса человека-оператора с робототехническим устройством.
ВВЕДЕНИЕ
Управление роботом на естественном языке в реальной среде приводит к потребности обработки сложных команд, когда целевой объект в команде может заменяться на местоимение, например “подойди к камню и исследуй его”. При рассмотрении частей данной команды независимо друг от друга: 1) “подойди к камню”, 2) “исследуй его”; теряется связь между местоимением и целевым объектом. Эта проблема существует в системах управления роботом, которые обрабатывают команды с одним действием без связи с предыдущими командами. Примером такой системы является нейросетевой интерфейс обработки сложных команд на естественном языке, описанный в [1]. Предлагаем решение с дополнительной обработкой команды по замене местоимения на целевой объект, упомянутый в предыдущем контексте. На рис. 1 изображена схема устройства разработанного интерфейса обработки команды от человека. В качестве инструментов применяем настроенные модели: базовую языковую T5 [2], позволяющую генерировать текстовые последовательности, и языковую модель на базе BERT [3], которая находит связанные слова в тексте команды [4, 5]. Определение связи между словами – это задача кореферентности. Для ее решения в общем в виде (поиск всех связанных слов в тексте, включая сложные компонентные высказывания) в [4, 5] использовали модели на основе нейросетей LSTM и BERT.
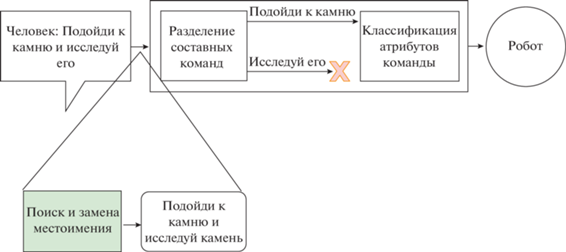
Таким образом, в работе описаны процесс создания набора данных на русском языке для настройки моделей RuT5 и RuBERT; модели и значения их гиперпараметров; используемые для оценки метрики, а также представлены результаты настройки моделей.
НАБОР ДАННЫХ
При составлении набора данных с командами на естественном языке, содержащими местоимения, использовали генератор команд [1] с применением библиотеки pymorphy2 [6] для согласования слов с числительными и приведения слов в нужную речевую форму. Данный генератор создает команды на естественном языке на основе заданных шаблонов и словарей с синонимами и речевыми оборотами русского языка [1]. Все шаблоны команд описываются следующим псевдокодом:
GENERATE (patience, pattern):
(patience – число итераций генератора
pattern – имя шаблона)
for patience do:
{выбор и подстановка случайных синонимов для шаблона pattern}
Пример шаблона: [действие] [объект] [дополнительные части речи]
{применение pymorphy2 к шаблону}
end for.
Генерацию команд для случая с местоимениями осуществляли комбинацией двух созданных команд по шаблонам и замене в одной из них объекта местоимением:
В общей сложности было получено около 20 000 уникальных команд, в табл. 1 показаны классы шаблонов (аналогичные классам [1]) с примерами, использованными при генерации. Сгенерированные команды отличаются друг от друга синонимами, типами действий над объектами, а также использованием инфинитивов, причастий и придаточных частей предложения.
Таблица 1.
Классы команд генератора
| Тип команды объекта | Целевой объект | Местоимение |
|---|---|---|
| Объект | Подойди к дому | осмотри его |
| Ближайший объект | Повернись к ближайшему дереву | иди к нему |
| 1 отношение | Найди камень рядом с деревом | анализируй его |
| 2 отношения | Найди дом около дерева рядом с машиной | подойди к нему |
| Отношение с роботом | Направляйся до дерева, что слева от тебя | объезжай его |
| Направление взгляда | Поворачивай к этому человеку | осматривай его |
При формировании выборок для настройки модели RuT5 в качестве выходных тренировочных данных размечали два варианта текста (табл. 2). В случае разметки 1 при помощи генератора команд создавали сложную команду с объектом и аналогичную ей команду с местоимением. Разметка 2 включает в себя использованные во время генерации слова: объект и местоимение.
Таблица 2.
Варианты разметки выходных тренировочных данных для RuT5
| Входная последовательность | Выходная последовательность |
|---|---|
| Подойди к дому и осмотри его | Команда: подойди к дому и осмотри дом |
| Поворачивай к этому человеку, осматривай его | Цель: человека его |
Для настройки модели RuBERT сгенерированный набор команд был токенизирован и размечен по следующему принципу: каждой команде ставятся в соответствие порядковые номера токенов, которые кодируют связанные в команде слова объекта и местоимения.
МОДЕЛИ
Использовали нейросетевую языковую модель RuT5 с архитектурой трансформер, предназначенную для понимания и генерации текста. Была проведена настройка двух версий модели “base” и “small”, различающихся количеством параметров. Их настройку проводили на двух размеченных наборах данных по примеру из табл. 2 с генерацией полной команды, в которой на место местоимения ставится целевой объект, и с генерацией пары “объект–местоимение” для последующей замены местоимения на предложенное слово. В процессе обучения были установлены значения гиперпараметров (табл. 3).
Таблица 3.
Значения гиперпараметров моделей ruT5-small и ruT5-base
| Параметр | Значение |
|---|---|
| Batch size | 32 |
| Epochs | 10 |
| Learning rate | 1e-4 |
| Max source text length | 48 |
| Max target text length | 48 |
Другая использованная языковая модель с архитектурой трансформер – это модель на базе RuBERT, которая является адаптацией модели [5], основанной на модели кореферентности, под русский язык [4]. Модель на базе RuBERT взята из библиотеки Tensorflow без какого-либо изменения значений гиперпараметров. Ее настройку осуществляли на протяжении пяти эпох.
ЭКСПЕРИМЕНТ
Для оценки использовали набор метрик разного типа. Первый – метрика BLEU оценки текстов машинного перевода [7]. Ее применяли для оценки сгенерированного ruT5 полного текста команды. Второй тип включает в себя набор метрик для оценки кореферентности, которые использовались в соревновании [8]. Данный набор метрик (описаны ниже) применяли как для оценки RuT5, которая генерировала пары “объект–местоимение”, так и для оценки RuBERT.
При оценке использовали тестовый набор из 1000 сгенерированных команд, аналогичных командам, описанным выше, но не пересекающихся с ними. Тестовый набор был размечен для оценки по метрике BLEU и по метрикам кореферентности. Оценка полного текста команды с использованием метрики BLEU для полного текста команды представлена в табл. 4.
Таблица 4.
Результаты оценки моделей RuT5 по метрике BLEU при генерации полного текста команды
| ruT5-base | ruT5-small | |
|---|---|---|
| BLEU | 93.6% | 95.0% |
Перед настройкой модели RuBERT был проведен эксперимент по оценке ее точности в исходной конфигурации с использованием обученного набора весов. Из табл. 6 видно, что эта точность RuBERT значительно ниже точностей настроенных RuT5.
Таблица 5.
Пример разметки тестового набора данных для оценки по набору метрик кореферентности
| Команда: повернись к булыжнику, переместись до него | ||||
|---|---|---|---|---|
| Слово | ID | Offset | Length | Chain ID |
| булыжнику | 1 | 12 | 9 | 1 |
| него | 2 | 38 | 4 | 1 |
Таблица 6.
Результаты оценки моделей ruT5 и RuBERT по метрикам соревнования [8]
| Метрика | ruT5-base | ruT5-small | RuBERT | RuBERT-fine |
|---|---|---|---|---|
| all_muc_recall | 98.6 | 85.6 | 39.4 | 99.0 |
| all_bcube_recall | 98.9 | 89.2 | 48.1 | 99.2 |
| all_ceafe_recall | 99.3 | 92.8 | 56.6 | 99.4 |
| all_muc_precision | 98.6 | 85.6 | 52.9 | 99.2 |
| all_bcube_precision | 98.9 | 89.2 | 64.4 | 99.3 |
| all_ceafe_precision | 99.3 | 92.8 | 76.5 | 99.6 |
| all_muc_fmeasure | 98.6 | 85.6 | 45.2 | 99.1 |
| all_bcube_fmeasure | 98.9 | 89.2 | 55.0 | 99.6 |
| all_ceafe_fmeasure | 99.3 | 92.8 | 65.0 | 99.5 |
| mean_fmeasure | 98.9 | 89.2 | 55.1 | 99.3 |
Для оценки по метрикам кореферентности тестовый набор данных был приведен в вид аналогично соревнованию [8]. Каждой команде из тестового набора ставятся в соответствие числовые значения, аналогично табл. 5.
В качестве метрик соревнования для оценки кореферентности использовали MUC, B3 и CEAF-e, описанные в [9]. Метрика MUC основана на минимальном количестве отсутствующих ссылок по сравнению с ключевыми объектами. Метрика B3 является показателем, основанным на упоминаниях, для каждого упоминания в ключевых объектах учитывается доля правильных упоминаний. Метрика CEAFE-e использует меру сходства для оценки сходства двух объектов на основе алгоритма Куна–Мункерса, который заключается в поиске максимального паросочетания. Результаты оценки со средним значением всех метрик представлены в табл. 6.
ЗАКЛЮЧЕНИЕ
Полученные оценки уровня точности нейросетевых языковых моделей демонстрируют, что модели генерации текстовой последовательности RuT5 и модель, решающая задачу кореферентности RuBERT, успешно справляются с задачей поиска и замены местоимения в команде на естественном языке.
В ходе исследования получены три варианта обработки команды от человека с местоимением: генерация полной команды, генерация пары “объект–местоимение”, определение взаимосвязанных слов в тексте команды. Последние два варианта дают более высокую точность, чем составление полной команды, но накладывают требования для поиска и замены найденных местоимений в исходной команде.
Использование моделей RuT5 по сравнению с моделью кореферентности на базе RuBERT требует меньшего количества памяти, что заметно сказывается на времени обработки команд, поступающих от человека.
Список литературы
Грязнов А.В., Скороходов М.С., Рыбка Р.Б. и др. // Вестник НИЯУ МИФИ. 2022. Т. 11. № 2. С. 143.
Colin Raffel, Noam Shazeer, Adam Roberts et al. // ar-Xiv:1910.10683. 2019.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Tou-tanova // arXiv:1810.04805. 2018.
Sboev A., Rybka R., Gryaznov A. // Advanced Technologies in Robotics and Intelligent Systems. 2020. V. 80. P. 35.
Joshi Mandar, Levy Omer, Zettlemoyer Luke, Weld Da-niel // Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. P. 5803.
Korobov M. // Analysis of Images, Social Networks and Texts. 2015. P. 320.
Papineni Kishore, Roukos Salim, Ward Todd, Zhu Wei-Jing // Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. P. 311.
Budnikov E.A., Toldova S.Yu., Zvereva D.S. et al. // D-ialogue Evaluation 2019.
Moosavi N.S., Strube M. // Association for Computational Linguistics. 2016. P. 632.
Дополнительные материалы отсутствуют.
Инструменты
Вестник Военного инновационного технополиса «ЭРА»